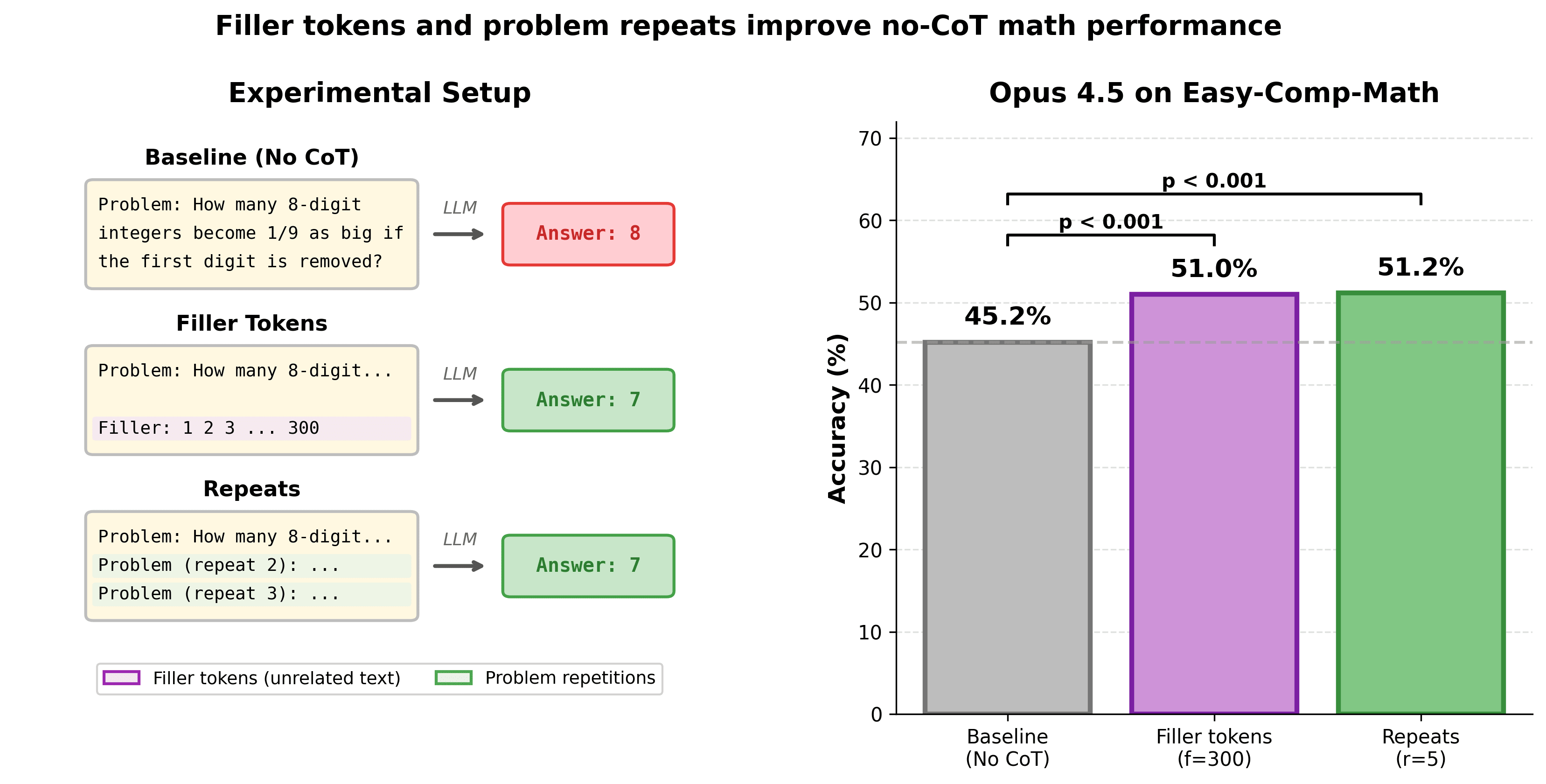
Prior results have shown that LLMs released before 2024 can't leverage 'filler tokens'—unrelated tokens prior to the model's final answer—to perform additional computation and improve performance.[1]I did an investigation on more recent models (e.g. Opus 4.5) and found that many recent LLMs improve substantially on math problems when given filler tokens.That is, I force the LLM to answer some math question immediately without being able to reason using Chain-of-Thought (CoT), but do give the LLM filter tokens (e.g., text like "Filler: 1 2 3 ...") before it has to answer.Giving Opus 4.5 filler tokens[2] boosts no-CoT performance from 45% to 51% (p=4e-7) on a dataset of relatively easy (competition) math problems[3].I find a similar effect from repeating the problem statement many times, e.g. Opus 4.5's no-CoT performance is boosted from 45% to 51%.
Repeating the problem statement generally works better and is more reliable than filler tokens, especially for relatively weaker models I test (e.g. Qwen3 235B A22B), though the performance boost is often very similar, especially for Anthropic models.The first model that is measurably uplifted by repeats/filler is Opus 3, so this effect has been around for a [...]
---
Outline:(03:59) Datasets
(06:01) Prompt
(06:58) Results
(07:01) Performance vs number of repeats/filler
(08:29) Alternative types of filler tokens
(09:03) Minimal comparison on many models
(10:05) Relative performance improvement vs default absolute performance
(13:59) Comparing filler vs repeat
(14:44) Future work
(15:53) Appendix: How helpful were AIs for this project?
(16:44) Appendix: more information about Easy-Comp-Math
(25:05) Appendix: tables with exact values
(25:11) Gen-Arithmetic - Repetitions
(25:36) Gen-Arithmetic - Filler
(25:59) Easy-Comp-Math - Repetitions
(26:21) Easy-Comp-Math - Filler
(26:45) Partial Sweep - Gen-Arithmetic - Repetitions
(27:07) Partial Sweep - Gen-Arithmetic - Filler
(27:27) Partial Sweep - Easy-Comp-Math - Repetitions
(27:48) Partial Sweep - Easy-Comp-Math - Filler
(28:09) Appendix: more plots
(28:14) Relative accuracy improvement plots
(29:05) Absolute accuracy improvement plots
(29:57) Filler vs repeat comparison plots
(30:02) Absolute
(30:30) Relative
(30:58) Appendix: significance matrices
(31:03) Easy-Comp-Math - Repetitions
(32:27) Easy-Comp-Math - Filler
(33:50) Gen-Arithmetic - Repetitions
(35:12) Gen-Arithmetic - Filler
The original text contained 9 footnotes which were omitted from this narration. ---
First published: December 22nd, 2025
Source: https://www.lesswrong.com/posts/NYzYJ2WoB74E6uj9L/recent-llms-can-use-filler-tokens-or-problem-repeats-to ---
Narrated by
TYPE III AUDIO.
---
Images from the article: